← Back to Blog | OpenAI's inflated valuation, as I understand it
| Talor AndersonSpecial thanks to Liz, Kent, and Ian at honeycomb for the discussion that inspired this article.
There's a strange thing happening in AI right now.
You might've heard some claims that we're in an AI bubble, the economy might be doomed, or from the other side that AI is about to revolutionize the world and AGI is right around the corner.
In trying to make sense of the situation, I've come to believe these things:
- LLMs will continue to improve – we're not hitting a "wall".
- LLMs will soon be generating trillions of dollars of economic value in the world.
- The valuations of big labs are too high even if they produce trillions in economic value, unless they capture significant portions of that value.
I see two paths where an AI lab could achieve their current speculative valuation, by capturing hundreds of billions to trillions of dollars in revenue:
- They invent superintelligence.
- All their competitors fold, leaving a monopoly by default.
I don't think either of these scenarios are particularly likely. Since neither path to meeting value expectations makes sense, the valuations are too high. That's bad news.
Let's break this down.
The state of things
First, let's establish the current valuations of the big model companies and other relevant players.
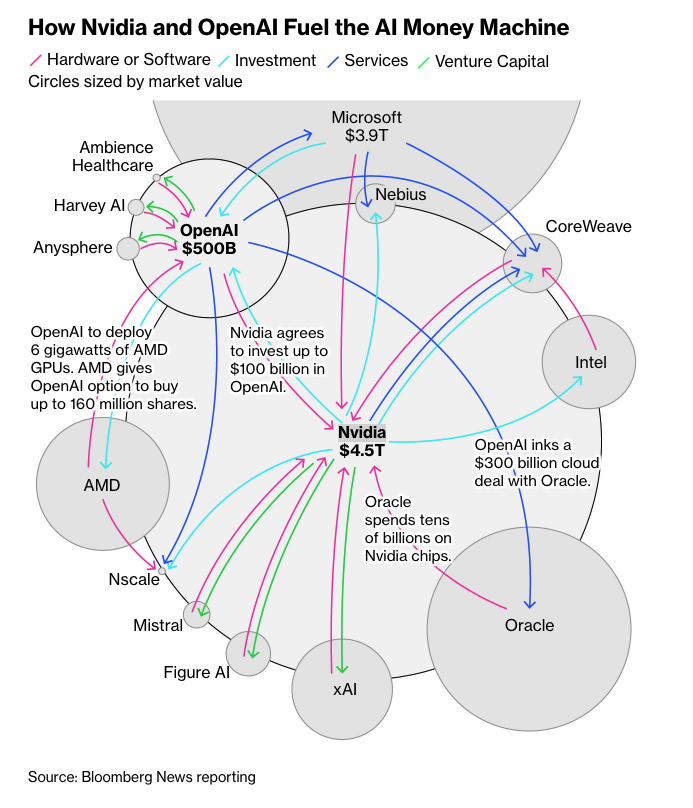
OpenAI is currently valued at $500 billion dollars.
Nvidia is currently valued at $4.3 trillion dollars.
If you're like me, these numbers probably mean very little to you on their own. I had no way to tell if these valuations are too high, too low, or just right.
Per the graph above, these companies and others like Microsoft are madly passing dollar bills back and forth. But is that such a bad thing? Everyone's buying stuff for a reason, right? OpenAI uses Microsoft's computing to train models. Microsoft uses OpenAI's models to write good code for their computers. Value is being created. There might be some inexplicable deals being made, but generally things seem fine.
So why is everyone talking about a bubble?
The reason, as you'll see below, is that these numbers are in fact too high to make sense. The companies are not worth this much. They're not worthless, which some will try to convince you of. I believe quite the opposite: AI companies are going to rule the world, the way traditional software companies have ruled the past 1-2 decades.
But I don't think it's going to go the way OpenAI and others are saying it will.
LLMs will continue to improve greatly in the coming years
I don't think we've hit a "plateau" in model intelligence yet, nor do I think it will happen soon.
(via DataStax)
This is a controversial take to some. Many, many people in tech and the media are saying we're hitting the "top of the sigmoid curve" in terms of LLM capability. We've discovered most of what there is to know, and training costs are going to be so expensive for new models that it'll stop being worth the cost to train more of them.
I disagree, and I bring it up because some will use this "plateau" as the justification for why the big AI labs are overvalued. I don't think that's the case.
The frontier is moving very fast: the first reasoning models only appeared a year ago (last september, when o1-preview was announced). Claude code has only been around ~8 months, and is now believably able to write 90%+ of a developer's code in certain cases. Devin, the first online coding agent, only appeared ~18 mo ago. Deepseek shocked us with unheard of price / performance ratio in early 2025, boasting a 30x lower price than o1-preview.
I believe even if it's true that models aren't improving at quite the same rate we've seen in the first few years of LLM development, incremental improvements actually become more valuable rather than less, as model capability increases.
The tasks that LLMs have been doing for us in the past few years have been chatbot-shaped: ask them stuff, and they'll give you an answer. Repeat ad infinitum. The latest generation of models aren't so much better than their predecessors at being chatbots. They still make mistakes and get confused or lost in chat sessions, and can't do basic things like math on their own. I think that misses the point of where LLM development is going today.
The new generation of models that have released in the past year are not just chatbots: they're trained to use tools to pursue a goal, aka act as agents. Instead of being evaluated on their responses, they're increasingly being trained on completing more and more complex tasks.
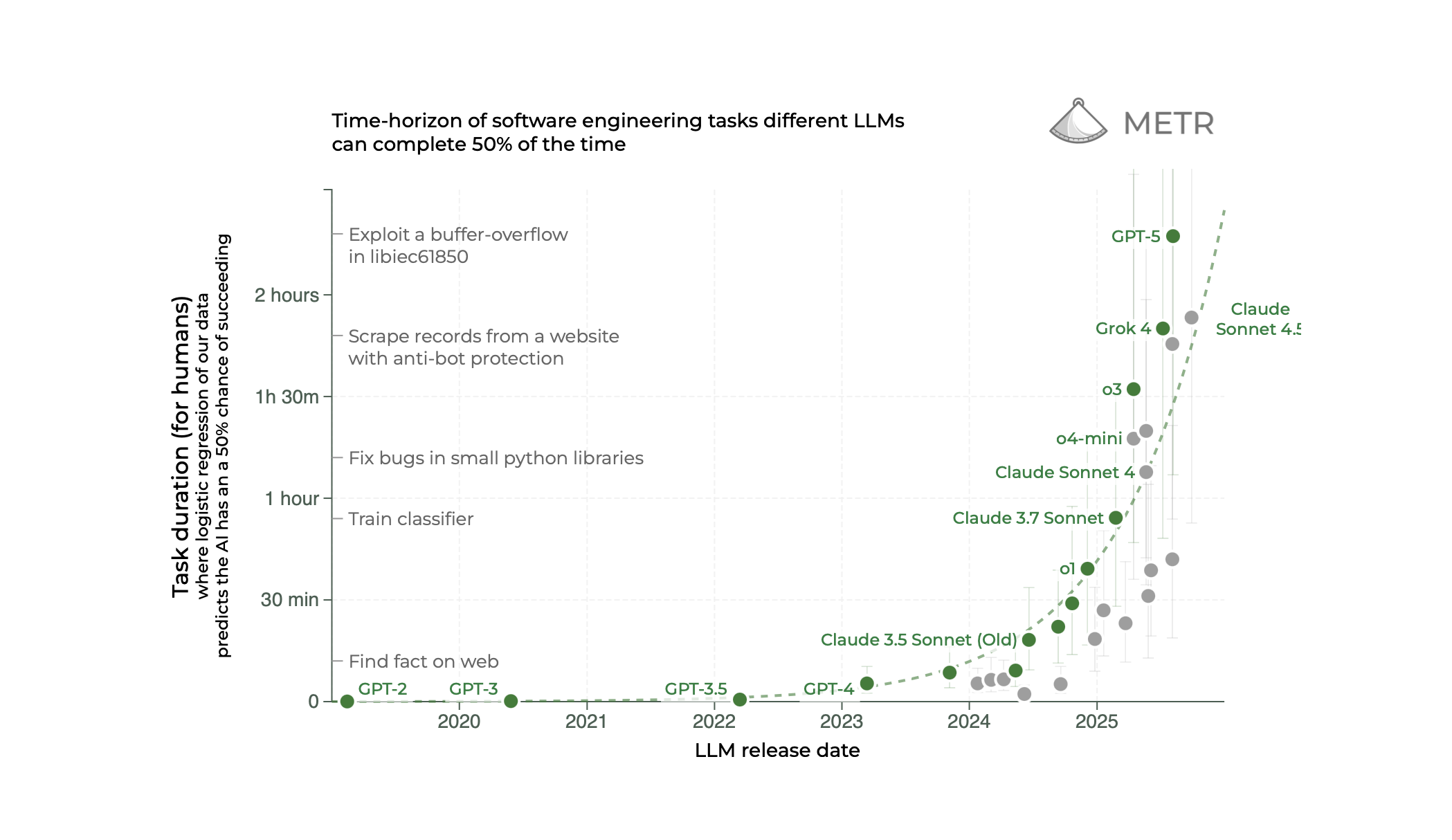
METR (Model Evaluation & Threat Research) claims from their studies that the length of tasks LLMs can complete is doubling every 7 months. Long tasks necessarily involve many, many operations in a row that the LLM must complete successfully to achieve the overall goal.
If a system succeeds at each step with probability p, the probability of success across n independent steps is p^n. For example, a 90% single-step success rate (p=0.9) over 10 steps yields only a 35% overall success (.9^10 = .35). Raising the per-step rate to 99% boosts the long-term success to 90% (.99^10 = .9).
An improvement from 90% -> 99% might not even be perceptible from casual use of an LLM (they'll still mess up once in a while), but an improvement from 35% -> 90% is huge. Each incremental improvement to a model that makes it even a fraction of a percent less likely to fail on a given task becomes increasingly important as overall goals grow in scope.
I believe LLMs will generate trillions of dollars of value annually within the next decade.
I believe we're just barely hitting the point where models can do broadly useful, economically valuable tasks outside the specific domain of software engineering.
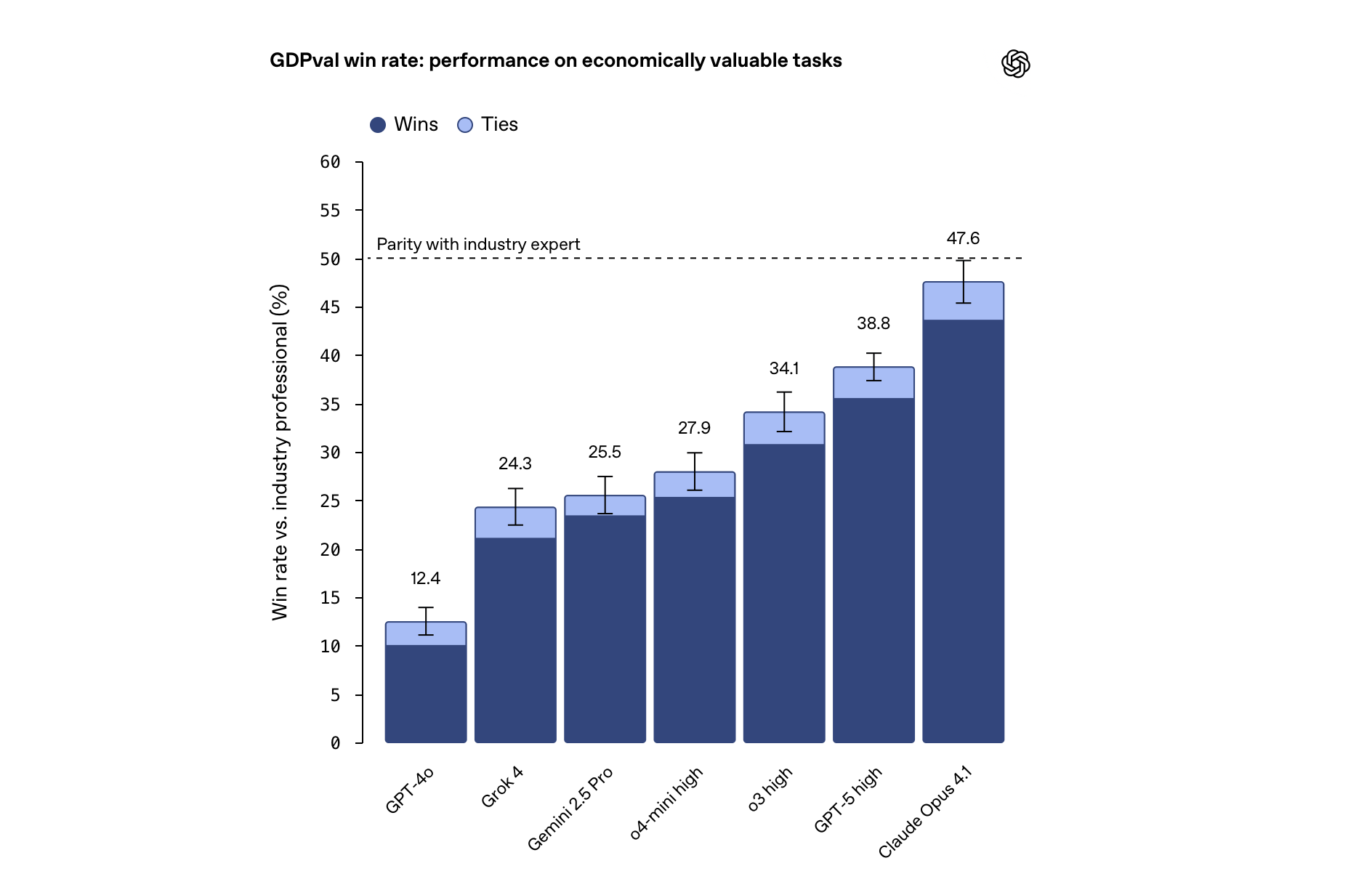
I am encouraged by the recent swathe of "general usefulness" benchmarks such as gdpval that measure more high level tasks outside of the coding vertical.
In the past year, we've seen an explosion of coding models with ever-growing capabilities. The labs have been hyper focused on getting performance on coding as high as possible.
We haven't yet seen the same for other general economic domains.
It's my view that:
- anything that is measurable can be optimized for
- lots of tasks are measurable, but haven't been
- lots of these measurable tasks are economically useful
coding has been hyperoptimized for thus far, but we've barely had much time at all to experiment with highly intelligent models optimized for general purpose tasks. I am using "highly intelligent" here to refer to the most recent class of models (o3, sonnet 4.x, gpt-5, et al), that seem to be able to perform better on longer horizon tasks than the generation of models previous that were mostly chatbot-like. I think there's probably still a lot of juice left to squeeze there.
I don't think LLMs will develop into "superintelligence" soon
AGI (Artificial General Intelligence) and ASI (Artificial Superintelligence) is a tricky thing to define. Models are already smarter than us in lots of ways. Claude 4.5 Sonnet and GPT-5 both know far, far more facts than I do. They speak every commonly known language fluently, can ID where a photo was taken just by looking at it, know roughly everything on wikipedia, and can use that knowledge in new and interesting ways to solve unique problems.
So, what other ways could we define "general intelligence" in a way that's different from what we have today?
One possible definition of AGI/ASI is a system that's capable of self-improvement at such a rate that once it's invented, it can never be caught up to by another system.
LLMs today require huge investments to train. Once they're trained, they don't really change much: they can be updated later to get slightly better, but each big lab today is restarting from scratch every time they release a new model, for the most part.
We do not have the ability today to significantly improve an LLM constantly and cheaply.
Any company that could solve this would probably outcompete all the other labs, to the extent that they might never catch up. Their model would continually get smarter, cheaper, and better, unlike the other labs who are burning huge piles of money on each new model generation.
I believe models will continue to get incrementally smaller, smarter, and cheaper to train. I believe those incremental gains will change quite a lot about our world, the work we do, and our economy as a whole. But I do not really believe we'll hit some magic unlock that snowballs into superintelligence, at least not soon. If we do, we should be having some very different conversations instead of this one.
AI labs will not capture all the value created by AI
I see three possible roads ahead for how big AI labs will compete with each other to make money.
- Compete on price and reliability against other, similar offerings, in a commodity market.
- Train a model that's so big, no one can compete with it. You are free to charge as much as you want for it. Your competitors pivot to other businesses or fold.
- Invent superintelligence.
LLMs today are a commodity good. In scenario 1, they continue to act this way. Just as Amazon's AWS, Microsoft Azure, and Google's GCP compete on price, features, and quality for mostly-interchangeable cloud products, big labs might compete for customers with a few big players emerging and many smaller niche competitors available in the market. At least three big labs are spending within the same order of magnitude of money to get models with similar performance. Google's Gemini 2.5 pro, OpenAI's GPT-5, and Anthropic's Claude 4.5 Sonnet each excel at specific tasks, but their capabilities broadly overlap enough that each can do most of the same tasks the others can. This says nothing of the other labs close behind: such as xAI's Grok, Meta's LLaMa, moonshot's Kimi K2, and Deepseek's R1 that lag only slightly behind in capability from the bigger labs. If this is the way the AI landscape continues to look for the foreseeable future, it means that users will pick and choose between models to meet their needs.
This does not support the current valuations of the big labs. They are not valued as commodities. OpenAI's valuation suggests that it will be collecting sizable revenue from every human on earth. We'll get to the valuation numbers below.
I've told you already why I don't believe scenario 3, "invent superintelligence", is likely.
This leaves only scenario 2 as the outcome that could possibly justify the valuation the labs are seeing.
There are two ways that the situation could play out, that lets OpenAI (or some other big lab) charge whatever they want to consumers.
These labs and the players involved are staking all of their investment on the idea that they'll build a model so good that no one else can compete with them, leaving them to charge whatever they want with no one else able to challenge them to drive prices down.
Every time a lab drops a new model – like OpenAI's GPT-5 – they're momentarily at the top of the world in terms of capability. They have the smartest, most reliable model. If you need the degree of intelligence that only that model can provide, OpenAI is free to charge whatever they want for it.
You get to remain at the top by:
- Developing new models faster than other labs: everyone is competing for talent, and the race is pretty even, so this doesn't seem to happen.
- running your competitors out of money.
It is only if you do not have competition that you can charge whatever you want. and it's only if you can charge whatever you want that you can capture all the gains in the market you're operating in. Otherwise, just as MSFT, google, and amazon today create vastly more value than they capture in the cloud business, there's no way for the AI labs to live up to their trillion-dollar valuations.
This is true even if you believe LLMs will create truly massive economic upside in the future (I do!).
The labs can't justify their valuation if we believe they are regular tech companies
Let's work from another angle. What would a normal valuation for a big AI lab look like?
Company values are usually determined as a multiple of their annual profit. This is called a P/E ratio: (Price / Earnings).
here are some typical P/E ratios:
- Traditional companies: P/E of 15-25
- Growth tech companies: P/E of 30-50
- High-growth tech: P/E of 60-100+
OpenAI's current valuation sits somewhere around $500 billion. They do not expect to turn a profit until at least the end of the decade.
Let's imagine that the total valuation of all major AI companies sits around $4 trillion total (NVidia alone currently exceeds this number, at $4.3T). We'll assume they want to settle at a P/E ratio of 30-40: very generous for companies that at that point are titanic in size.
A $3T market cap divided by a 35 P/E ratio leaves us with around $85 billion in annual profit needed to justify the valuation.
Let's assume AI companies also settle around 20% profit margin. Cloud providers like GCP and Azure range between 20-30% profit margins today, and AI is much more costly to serve at scale.
this leaves us with $425 billion in annual AI-related revenue to justify our original valuation numbers. if every single working american, 163 million of them, purchased a chatgpt subscription at $20/mo, that would pencil out to about $40 billion per year: less than 10% of the revenue we need. We either need 10x as many subscribers as there are working Americans, let alone Americans with jobs that can reasonably be assisted by AI, or hundreds of millions of people paying thousands per year on AI services.
How we got here, or: How Much a Dollar Cost
How did valuations ever get this high to begin with, when the napkin math just doesn't work out, even to someone like me who is (1) very pro-AI, and (2) barely a casual student of economics?
I see two possible options:
- the market believes we'll build superintelligence, and we'll do it soon.
- the companies are in too deep to back out without losing their sunk costs.
There's an interesting phenomenon in game theory called the dollar auction that might explain what's happening in AI investment.
It was Liz who introduced me to the concept this way:
Imagine I tell you that I am auctioning off $100, but with a twist: the first and second bidders both must pay their bid at the end of bidding. The bidding starts at a dollar. It is rational for you to, when you are in second place, having already lost a bunch of money, keep on escalating the bid higher even if you will net a loss. The bidding does not stop at $99. Because the party that stands to lose $98 will bid $100 so as to get $100 back and so forth. This is the only way I can imagine a number of very very rational investors and sovereign wealth funds are throwing this much money into what they know has a high likelihood of not panning out for all but the most resourced player.
Like we saw before, companies have to continue spending billions to train new generation models constantly. This mirrors making yet another increasingly expensive bid to out-compete your opponent, who will do the same thing right back. Everyone needs the best model, so everyone needs to keep spending money.
I am not sure how this ends. I only see a few win conditions where one player emerges entirely victorious:
- they build AGI like they promised, and no one else can catch up to their technology.
- everyone else runs out of money and pivots or folds, so no one else can catch up to their monetary advantage. They are the only one who can train the most expensive model.
I see a third option being the most likely:
The money runs out for everyone without a single player being so far ahead that they can never be caught up to. The market corrects. Billions in speculative investment are wiped out. We re-emerge into the commodity AI market for the long term. I believe this is the most likely case for a few reasons:
- It's happened before: the dot com boom was just like this. Valuations were out of control, but the internet today is more economically valuable than anyone ever dreamed back then. It was painful for a while, but we're doing just fine now.
- No one is very far ahead yet. Anthropic, Google, and OpenAI are neck-and-neck on benchmarks, and other labs pop up constantly with new ideas and surprising performance. Researchers are being poached back and forth between labs constantly.
What's one to do?
Where do we go from here?
I have no idea. I do not know how to prepare for a market correction that seems to be growing more likely every single day.
Until the chat with my coworkers that spurred me to write this blog, I was skeptical of the idea of a bubble at all. I believe AI to be one of the most important inventions of my lifetime. How could it be over valued? If anything, it seems like no one was realizing how powerful AI is, and how fast it's improving. I thought it might be under valued!
I've come out the other side of this blog with a somewhat conflicting set of ideas:
- I believe we still aren't even close to realizing the total economic upside of AI, and yet
- The companies are overpriced, and a correction is probably inevitable.
Do you agree? Am I mistaken? If one believes in AI long term but not in the short, what should you do to prepare? I would love to hear from you. The facts of the situation now feel quite clear to me. I hope you feel the same after reading this. But what will the second and third order effects of a correction be?
That's all for now, thanks for reading.
– ta